4.3. Hash, Lookup and Dictionary¶
Both Python and Java use collections that depend on hashes. In Python hashed dictionaries are integral to attribute access. In both languages, it is important for the use of collection types (sets and maps), that two objects considered equal should also have the same hash.
Code fragments in this section continue in
rt3/src/main/java/.../vsj3/evo1and corresponding test and other directories in the project source.
4.3.1. The Type str¶
We implement Python str by the canonical class PyUnicode,
and we adopt java.lang.String as an implementation.
This follows the pattern already explained in Operations on Built-in Types.
We can generate many of the special methods,
including the comparison functions,
with the script PyUnicode.py.
PyUnicode holds an array of Java int representing the code points.
A representation may eventually be possible that
provides more variety of storage internally (like CPython),
but not just yet.
In practice,
most instances of str will be represented by java.lang.String,
and so compact representations would mostly benefit sub-classes of str.
We obtain an accurate interpretation of String
in mixed operations with PyUnicode
by wrapping the String temporarily in a Java iterable
(a sub-class of PySequence.Delegate)
yielding Integer elements.
Each PyUnicode holds such a delegate already as a non-public member.
Operations on str are largely operations on these delegates.
There is a dilemma around giving a proper interpretation
to a String involving UTF-16 surrogate pairs,
where consistency requires extra checks at run-time.
A Python str is effectively a sequence of Unicode code points,
while a Java String is a sequence of UTF-16 code points.
Both allow “code violations” of their own sort:
str allows code points for high and low surrogates
to appear as isolated pseudo-characters, even high followed by low;
String also allows isolated surrogate code points,
but a combination of high and low (in that order)
encodes a single supplementary plane character.
Since we may get such a String encoding supplementary characters at any time,
say from Java library call or a file,
we must treat pairs as single characters in them.
In adopting String as an implementation,
the delegate takes care of this in operations where we iterate,
involve the (Python) length of a string,
or return a PyUnicode.
4.3.2. Plain Object Keys and dict¶
It is important in the use of collections,
that two objects considered equal should have the same hash.
We may readily satisfy this constraint in Python
by careful definition of __hash__ and __eq__ across types.
A Python collection must determine equality using __eq__(Object, Object)
and hash using __hash__(Object), and all will be well.
A Java collection will determine equality using Object.equals(Object)
and hash using Object.hashCode().
In VSJ2 we were pleased with the simplicity of implementing dict as:
class PyDict extends LinkedHashMap<PyObject, PyObject> // ...
We could operate on dict instances
through the API of LinkedHashMap directly.
We shall explain why this is no longer an option.
Although the problems we discuss afflict
all types that have adopted implementation classes,
and any where distinct types are deemed comparable in Python,
we’ll discuss it in the context of str and int keys.
Problems Posed by Object.hashCode()¶
The formula by which Strings are hashed in Java
is part of the language specification.
It is not specified in Python,
so we could reasonably define str.__hash__
as equal to String.hashCode() for String implementations of str,
and by the same formula for PyUnicode.
We do so in PyUnicode.__hash__() and PyUnicode.__hash__(String),
so are guaranteed that equal strings will hash to the same value.
(We have to take a little care to handle supplementary plane characters
as if they were actually represented by a surrogate pair.)
Java defines Integer.hashCode()
and BigInteger.hashCode() consistently.
But we come unstuck with Boolean.TRUE and Boolean.FALSE,
which Java hashes to 1231 and 1237,
but Python to 1 and 0 respectively.
Python also defines float.__hash__ to be equal to int.__hash__
for values it deems equal.
None of this alignment exists across Java types, so we have here a compelling reason why Java containers based on key hashing cannot be used directly as the implementation of Python containers. However, we shall strengthen the argument by looking at equality.
Problems Posed by Object.equals()¶
We can define PyUnicode.equals(Object)
to accept String or PyUnicode and compare using
the Python Comparison.EQ.
This will deal correctly with u.equals(s) encountered in Java,
where u and s are PyUnicode and String respectively.
Do not mistake s here for a bytes object
(PyString as it was in Jython 2).
Both u and s are instances of str.
Let us suppose these u and s are equal
according to the rules of Python.
In the midst of a call map.get(u),
in the depths of LinkedHashMap,
this test will identify correctly
an entry previously made with map.put(s).
However,
map.get(s) will not correctly retrieve
an entry previously made with map.put(u),
because s.equals(u) is false.
String.equals(Object) is false if the argument is not a String.
Likewise,
BigInteger.equals(Object) will return true only if
the other object is a BigInteger.
The several implementations of int
(and bool and float)
will therefore not report as equal when used as keys in a Java container
although Python requires it.
Changes to dict¶
These considerations mean that
we cannot use Python objects as keys in Java containers,
and obtain Python semantics in the index operations.
(Python 1 and True would index different entries, for example.)
In particular we cannot implement PyDict
simply by extending the Java container LinkedHashMap,
although otherwise it seems the perfect choice.
Instead, we shall use a Java LinkedHashMap internally,
but have to wrap our keys so as to compare them using Python semantics.
PyDict will implement java.util.Map,
but we have to do more work than before to implement the API.
This idea is illustrated here:
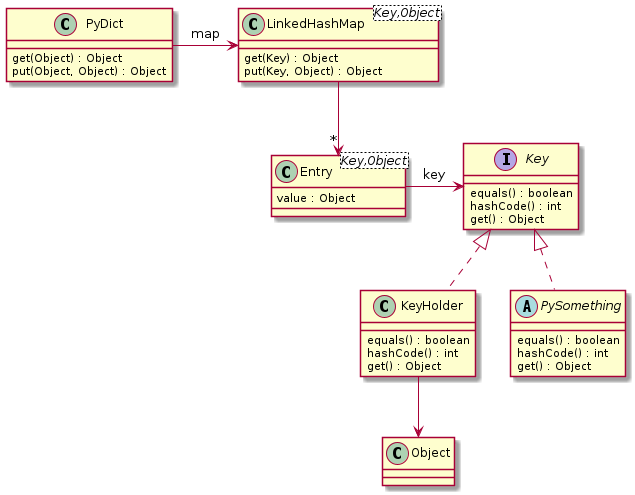
Giving Python semantics to keys¶
Each key in the member map implements the Key interface.
A KeyHolder is an object we create to wrap
the key received by PyDict.put,
so it may participate in a Map.Entry<Key, Object>.
We must also wrap the argument to PyDict.get,
so that we may search map with it.
The code for these two methods is simply:
class PyDict extends AbstractMap<Object, Object>
implements CraftedType {
static final PyType TYPE = PyType.fromSpec( //
new PyType.Spec("dict", MethodHandles.lookup()));
/** The dictionary as a hash map preserving insertion order. */
private final LinkedHashMap<Key, Object> map =
new LinkedHashMap<Key, Object>();
@Override
public Object get(Object key) {
return map.get(toKey(key));
}
@Override
public Object put(Object key, Object value) {
return map.put(toKey(key), value);
}
// ...
In order to extend AbstractMap,
PyDict must also implement a custom method
Set<Entry<Object, Object>> entrySet(),
the set that backs it,
and an iterator on the entry set.
This is all fairly standard: the library gives us the apparatus we need.
Now, wrapping every key is an overhead. While it is a necessary one, to support the plain object paradigm with adopted implementations, we may avoid it much of the time.
Where we can redefine equals() and hashCode(),
we’ll allow the objects themselves to be the keys.
For this reason the class diagram shows an example built-in PySomething
implementing PyDict.Key.
Crafted implementations may implement PyDict.Key,
while adopted ones cannot.
It remains an open question whether discovered Java types
should be treated as keys directly or wrapped.
There seems no need to give them Python semantics in this respect,
so whatever hashCode() and equals() they define
could probably stand.
This would force map to become a Map<Object, Object>.
There may be a case for having the Operations object
provide a PyDict.Key,
since it differentiates by Java class within a common type.
4.3.3. Attribute Names¶
Many Python objects,
including the type object,
allow the programmer to define new attributes.
It is evident that one is dealing with a dictionary,
since there is a __dict__ in which the definitions may be seen.
>>> class C:
a = 42
>>> C.__dict__.keys()
dict_keys(['__module__', 'a', '__dict__', '__weakref__', '__doc__'])
>>> c = C()
>>> c.b = 43
>>> c.__dict__
{'b': 43}
We may put any type of key in the dictionary of an instance, but that doesn’t make it an attribute. Attributes names have to be strings:
>>> c.__dict__[True] = 99
>>> c.__dict__
{'b': 43, True: 99}
>>> c.True
SyntaxError: invalid syntax
>>> getattr(c, True)
Traceback (most recent call last):
File "<pyshell#162>", line 1, in <module>
getattr(c, True)
TypeError: getattr(): attribute name must be string
When we access an attribute from program text (as in c.b above),
the name is embedded in the code object co_names table as a str,
and that value is used in a LOAD_ATTR opcode,
which invokes the special method __getattribute__.
>>> code = compile("c.b", '', 'eval')
>>> code.co_names
('c', 'b')
>>> from dis import dis
>>> dis(code)
1 0 LOAD_NAME 0 (c)
2 LOAD_ATTR 1 (b)
4 RETURN_VALUE
Python allows a wide range of non-ASCII identifiers to be used in program text (PEP 3131). Despite examples of the creative use of supplementary characters, we work on the assumption that supplementary plane characters are rare in attribute and variable names.
We propose therefore to represent names appearing in programme text
by java.lang.String objects exclusively.
A supplementary plane character in a name must be encoded as UTF-16.
The name in attribute access special methods
__getattribute__, __getattr__, __setattr__ and __delattr__
will be strongly-typed as String.
(This does not apply to their counterparts __getitem__, etc.,
which must accept arbitrary objects as their index.)
In all the places where we call attribute access methods,
including through the op_* slots of an Operations object
in which they are cached,
we shall be in control of the Java type finally passed.
Where an object representing a name enters from Python code,
for example in the getattr() built-in function,
or a direct call to object.__getattribute__,
we may arrange an appropriate conversion at the boundary.
(It is just PyUnicode.toString().)
This does not limit the available identifiers in any way. Only the representation of names is optimised to favour lookup of identifiers that use only BMP characters.
4.3.4. The Dictionary of a PyType¶
Every Python type object contains a mapping
from attribute names to values,
which are often descriptors.
This mapping is exposed through type.__dict__,
but only as a read-only mappingproxy.
The type may allow changes to the set of attributes,
but only via a mechanism it can police,
and follow up with changes to internal data if necessary.
Only str keys ever appear in this dictionary.
This could be implemented by a regular dictionary (PyDict),
but we take advantage of the greater control we have.
The representation of names exclusively by java.lang.String
allows us to use a Java implementation directly in PyType,
specialised to type.
We avoid the extra apparatus in PyDict
needed to recognise keys of differing Java class as equal:
the delegation of get and put,
and the wrapping of keys to take control of hashCode and equals.
class PyType extends Operations implements PyObjectDict {
// ...
private final Map<String, Object> dict = new LinkedHashMap<>();
// ...
Object lookup(String name) {
// Look in dictionaries of types in MRO
PyType[] mro = getMRO();
for (PyType base : mro) {
Object res;
if ((res = base.dict.get(name)) != null)
return res;
}
return null;
}
Object lookup(PyUnicode name) {
return lookup(name.asString());
}
@Getter("__dict__")
@Override
public final Map<Object, Object> getDict() {
return Collections.unmodifiableMap(dict);
}
For the time being,
type.__dict__ is a plain Java object implementing Map,
but this needs uplifting to a mappingproxy when we have it.